
by Patrick J. Lynch
and Sarah Horton
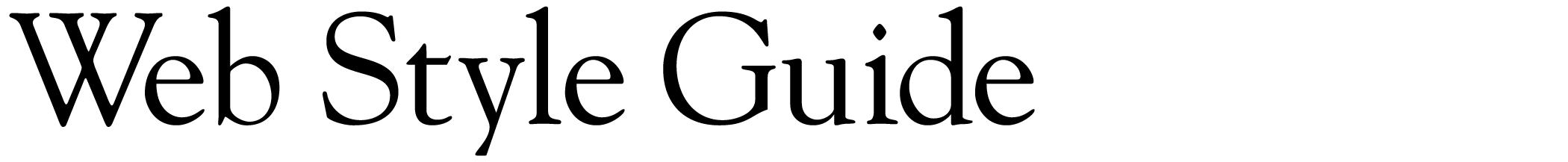
5 Site Structure
Site File Structure
Like the inner workings of a fine watch, the internal details of your site are craftwork that only other technologists will see, but your users will benefit from careful planning and thought. Discussions about site and page structure usually center around the most visible aspects of navigation, user interface, and content organization, but attention to the file and directory structure and how you name things within your site can produce big payoffs in:
- Understanding: Your current team, future site maintainers, and most site users will benefit from careful, consistent, plain-language site nomenclature
- Flexibility: If every object in your site has a name, everything can be found, styled, and programmatically manipulated much more easily
- Accessibility: Named objects are more accessible to programmatic and style sheet control across all media types and give you flexibility in implementing universal accessibility features in your site
- Search optimization: Careful site nomenclature makes it much easier to optimize a site for search engine visibility
- Future growth and change: you can’t scale up or automate changes in a randomly named, haphazardly constructed collection of files and directories; a nonsystem can’t be systematically managed or structurally expanded
The hidden semantics of sites
The goal of semantic organization of your site is to produce a consistent, logical system of classifications for html and other files, directories, css components, and the various logical and visible divisions within your page templates. A consistent, modular approach to site construction can be scaled from small sites containing a dozen pages all the way up to content-managed sites consisting of tens of thousands of pages. Although we can present general principles for site structure here, the technical environment and functional demands of many sites may require particular forms of file naming. The fundamental point is that, whatever your site environment, you should develop systematic rules for naming every component of your site, make sure that everyone in the team understands and follows those rules, and use plain language wherever possible.
Naming conventions
Never use technical or numeric gibberish to name a component when a plain-language name will do. In the early days of personal computing, clumsy systems like ms-dos and Windows 3.x imposed an “eight-dot-three” file name convention that forced users to make up cryptic codes for file and directory names (for example, “whtevr34.htm”). No word spaces and few non-alphanumeric characters were allowed in file names, so technologists often used characters like the underscore to add legibility (for example, “cats_003.htm”).
Habits developed over decades can be hard to break, and looking into the file structure of another team’s site can sometimes feel like cracking the German Enigma codes of World War II. Current file name conventions in Windows, Macintosh, and Linux systems are much more flexible, and there’s no reason to impose cryptic names on your team members, site users, and colleagues who may one day have to figure out how you constructed your site. There’s an old saying in programming that when you add explanatory comments to your code, the person you are mostly likely doing a favor for is yourself, three years from now. Three years from now, will you know what’s in a directory called “x83_0001”?
Naming pages, directories, and supporting files
Although we think of web pages and their graphics as a unit, web page files do not contain graphics but consist instead of embedded links to separate graphics files. These embedded image links (<img src="graphic.jpg" alt="example">) are used by the web server to deliver a package consisting of an html file, plus all associated graphics, css or JavaScript files, and other media files. Most web “pages” are actually a constellation of files delivered to and assembled by the browser into the coherent page we see on our screens. Attention to file and directory names is essential to keeping track of the myriad pages and supporting files that make up a web site (fig. 5.2).

Figure 5.2 — The constellation of twelve component files that form this web page.
Use language that anyone can understand
Use plain-language names for all of your files and directories, separating the words with “breaking” hyphen characters. This system is easy to read and understand, and since conventional word spaces are not allowed, the hyphens “break” the file name into individual words or number strings that can be analyzed by search engines and will contribute to the search rankings and content relevance of your pages. We recommend this convention for directory names, too.
Mirror your visible site structure wherever possible
Directory and file naming conventions that directly mirror the visible organization of your site are infinitely easier for your team and users to understand and will contribute to search engine rankings and relevance, because the whole url becomes a useful semantic guide to your content structure. Each component of your page url can contribute to search page ranking, but only if the names make sense in the context of your page content and relate to key words or phrases on the page.
This poorly named url contributes nothing to search engine relevance or site structure legibility:
www.whatever.edu/depts1/progs2/org004/bio_424.html
In contrast, anyone (and any search engine) can parse this plain-language content arrangement at a glance:
www.whatever.edu/departments/biology/ornithology/field-ornithology-bio-224.html
Always try to mirror the visible structure of your site’s content organization in the directory and file structure you set up on the web server (fig. 5.3).
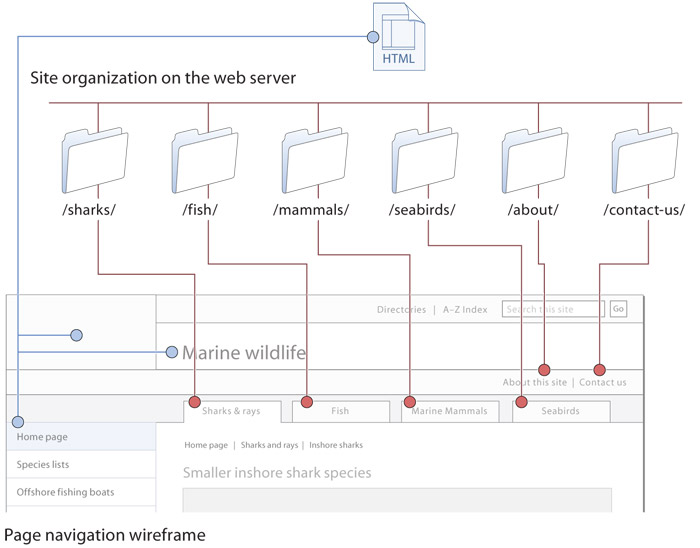
Figure 5.3 — Try to mirror the major interface and content divisions when you structure the HTML and directories of your web site.
Structure for efficiency and maintainability
Well-designed sites contain modular elements that are used repeatedly across many dozens or hundreds of pages. These elements may include the global navigation header links and graphics for the page header or the contact information and mailing address of your enterprise. It makes no sense to include the text and html code that make up standard page components in each file. Instead, use a single file containing the standardized element that repeats across hundreds of pages: when you change that one file, every page in your site containing that component automatically updates. html, css, and current web servers offer the power and flexibility of reusable modular components, and most large, sophisticated sites are built using dozens of reusable components.
Include files
Web servers allow site authors to create standardized pieces of html code, called “include files,” that can be used across all pages in a web site. An include file is just a text file containing ordinary html page code. When a user requests a page, the web server combines the main page with whatever include files are specified in the main page file, and the assembled html page is then sent to the user’s browser (fig. 5.4).
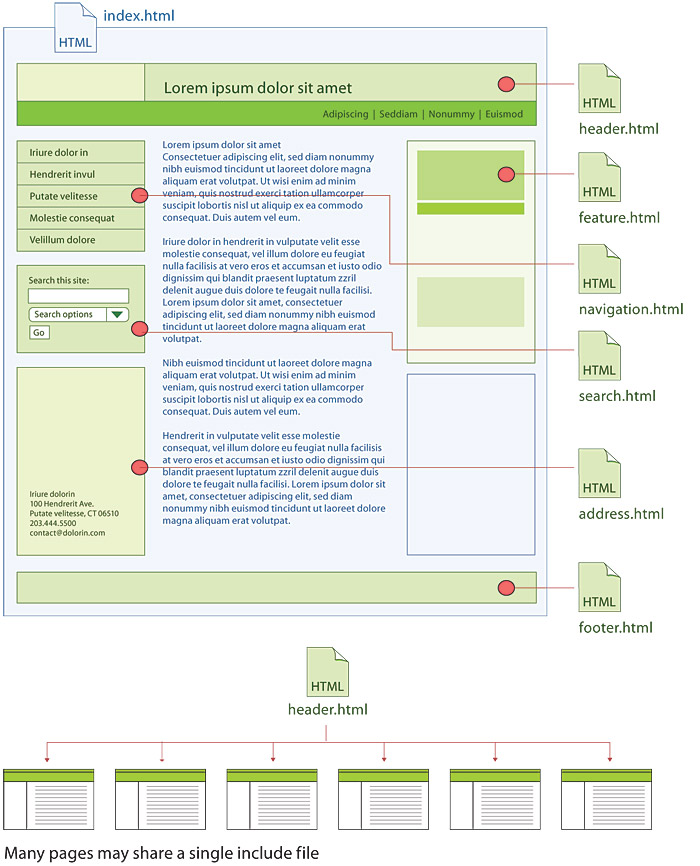
Figure 5.4 — Include files are a powerful way to reuse standard components across many pages instead of repeating the HTML code over and over again on each page.
Include files can also be handy for repeating standardized content such as payment policies, privacy policies, or other “boilerplate” business or legal language that is repeated in identical form in many places throughout a large site. Always look for opportunities to pull repeating content out of the page files and into an include file. If you ever have to change the boilerplate language, you’ll be glad you have to change just one file to update every occurrence of the text throughout the site.
Using the cascade in CSS
Many users of Cascading Style Sheets know how to change the look of standard html components but don’t pay much attention to the powerful cascade features of css. css is an extendable system, in which a related set of css instructions spread across multiple css files can cascade from very general style and layout instructions shared by all of your pages to extremely specific styles that only a handful of pages in your site may share. The css cascade has two major elements:
1. CSS cascade hierarchy
css has multiple hierarchical levels that cascade in importance and priority, from general css code shared by all pages, to code that is contained in a particular page file, to code that is embedded in specific html tags. General page code overrides shared site code, and css code embedded in html tags overrides general page code. This hierarchical cascade of css priorities allows you to set very general styles for your whole site while also permitting you to override the styles where needed with specific section or page styles (fig. 5.5).
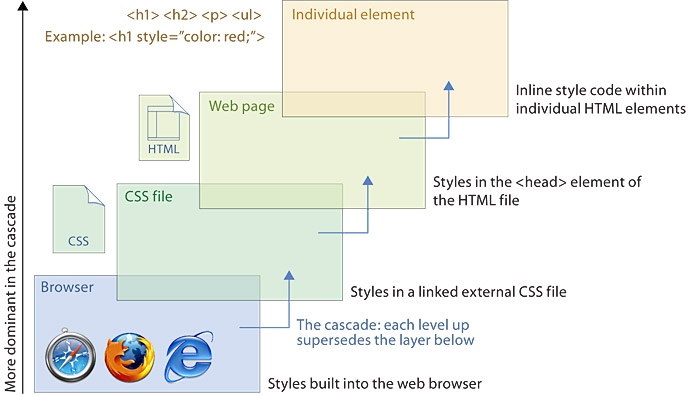
Figure 5.5 — Each level of the style sheet “cascade” overrides the one below. Thus you can use very general styles but also add code to customize individual elements where necessary.
2. Shared CSS across many pages
Multiple css files can work together across a site. This concept of multiple css files working together in a modular way is the heart of the cascade system of pages that all share code via links to master css files that control styles throughout the site. This system has obvious advantages: if all your pages share the same master css file, you can change the style of any component in the master css file, and every page of your site will show the new style. For example, if you tweak the typographic style of your <h1> headings in the master file, every <h1> heading throughout the site will change to reflect the new look.
In a complex site, page designers often link groups of css files to style a site. Packaging multiple css files can have many practical advantages. In a complex site css code can run to hundreds of lines, and it’s often more practical to subdivide such elements as the basic page layout css from the master site typography styles. It’s easy to link to css files and let the master css layout and typography styles control all the pages in your site.
CSS “skin” files for specific graphic treatments
You may not want every page or section of your site to look the same. If so, you can add a third “skin” css file that provides specific graphics, colors, and header treatments for all pages in a site section that share the same visual design. Each css file in the multifile cascade adds information, moving from sitewide general layout and typographic styles to visual styles that may be specific to a few pages (fig. 5.6).
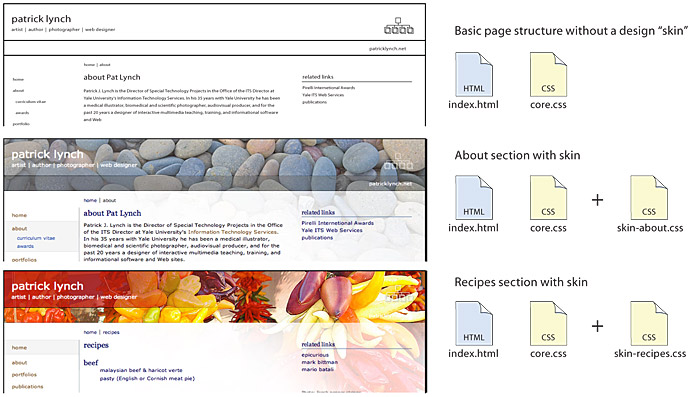
Figure 5.6 — A barebones page layout (top) and two different “skins” that use CSS to add customized graphics.
Media style sheets
Another advantage of css is the ability to provide context-appropriate designs using media style sheets. Support for media style sheets is not all that it could be, but there is sufficient support for screen, print, and, to a lesser degree, handheld devices. With media style sheets, it’s possible to adapt a layout, for example, to hide navigation elements when printed or to minimize menu options when viewed on the small screen of a cell phone.
Semantic structure for HTML content containers
As you plan the page wireframe templates for your site, consider the advantages of careful semantic html and css within the individual html files. Well-designed, standards-based web pages consist of many subdivisions that not only lay out functional regions of the page (header, footer, scan column, navigation, search box) but also provide unique name “ids” for all standard page template elements. The content portions of web pages are subdivided by divisions (<div>…</div>) and spans (<span>…</span>) that label functional areas of the page, providing a “wrapper” around specific page elements or types of content. Divisions and spans should always be named carefully, and major repeating page elements should each have a unique id.
These named divisions and spans are crucial for three reasons:
- Uniquely named page elements give you complete programmatic and style sheet control. You can’t address a page element with css or JavaScript unless it has a name.
- Uniquely named page divisions allow you to apply css visual styles more easily and powerfully to particular page areas or blocks of content.
- Uniquely named page areas will give you many more options in the future, as new web content display devices and types of style sheets are developed. Someday you may want to convert your site to a new content management system. If all your pages and content are contained in consistent, systematically named page divisions, transforming your site will be much easier.
As you develop page wireframes and basic navigation, build in the power and convenience of careful semantic naming of your page regions and major page elements. It’s easy to do in the beginning of a project and very hard or impossible to do later (fig. 5.7).
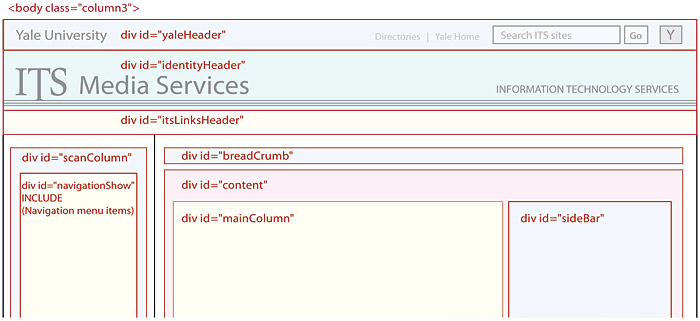
Figure 5.7 — The top section of a detailed page wireframe diagram for the site technical team that shows all the various page divisions (divs).







